数据分析之Pandas
Pandas中两大数据结构:DataFrame、Series。
数据文件的读取。可以读取excel、csv、tsv等数据文件。下面以csv文件为例
1 | import pandas as pd |
具体可以指定的参数有:
encoding,文件编码方式,如:
GBK/ANSI/UTF-8names,指定数据文件的各个列的名称,传入的是list类型
seq,指定文件的分隔符
查看数据相关信息
1 | df.head() |
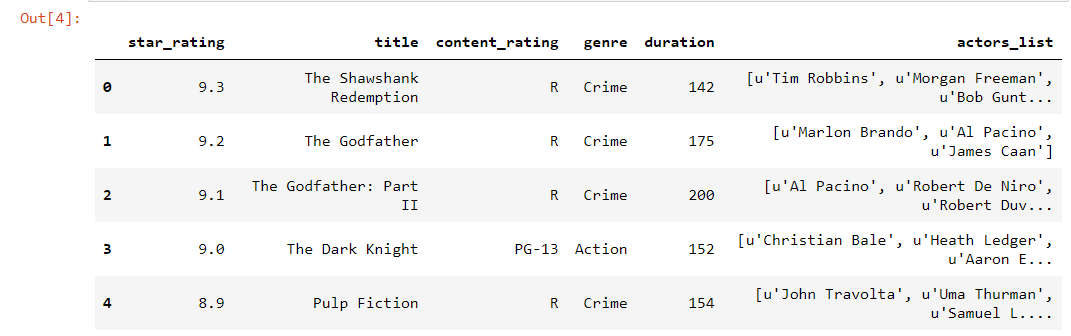
1 | df.info() |
获取数据的统计信息:df.describe()
1 | df.describe() |
获取某一列或多个列的值
通常将要获取的多个列名包装到list中。
1 | #获取评分这一列的值,返回一个Series对象 |
注意:不能这么写:df[[0,1,2,3]]
获取某一行或多行的数据
1 | #直接切片获取 |
还是推荐使用loc或者iloc来进行行的获取。这样更加直观。
iloc和loc
使用形式:loc[,]/iloc[,]
1 | # 获取指定索引的数据,比如获取第10部电影的数据 |
注意:获取某一特定index行,不可以直接df[index],需借助df.loc[index,:]函数。
loc不仅可以传入索引、列表、切片获得指定数据,还可以传入条件进行筛选,具体参见下一小节。
iloc在列的选取上与loc不同,loc传入的是列名;而iloc传入的是列的索引。
1 | #介绍df.iloc使用, iloc是按位置选取的,传入的参数都是整数 |
获取满足特定条件的行
1 | # 获取电影时长在120min以上的电影,返回一个DataFrame |
查看不同分级的电影数量
1 | # 获取电影具体的分级级别 |

groupby的应用
1 | #查看不同题材的电影的平均时长 |
apply、map、applymap
apply传入一个函数,会将该函数应用于选中的列
applymap是指将函数应用于DataFrame的所有元素
1 | import numpy as np |
1 | #获取电影主演的第一个演员的名字 |
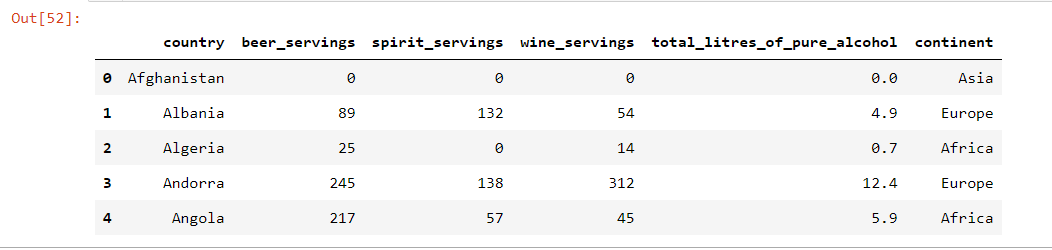
下面引入一个新的数据集
1 | drinks = pd.read_csv('http://bit.ly/drinksbycountry') |
1 | # 在DataFrame中,可通过axis指定appply作用在行或者列上 |
在DataFrame中删除行或者列
1 | # 删除一列或多列 |
在DataFrame中给某一列重命名
1 | # 获取所有列名 |
也可以通过在read数据时,指定names参数来指定列名(names = df_cols)
1 | # 也可以.str来使用Series中封装的字符串方法 |
给某一列进行排序
1 | # pandas.Series.sort_values(ascending=True, inplace=False) 默认升序,且不改变原Series结果 |
发现并删除重复行
1 | # pandas.Series.duplicated() 返回bool的series |