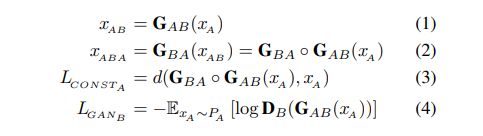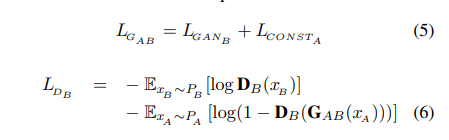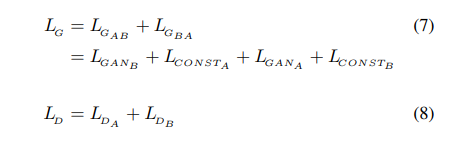生成对抗网络(GAN)
1. 入门简介
gan整体的损失函数
训练时,先训练Discriminator、然后训练Generator,迭代直至目标函数收敛。
需要注意的是,一切损失计算都是在D(判别器)输出处产生的,而D的输出一般是fake/true的判断,所以整体上采用的是二分类交叉熵函数。
首先看一下maxD部分,因为训练一般是先保持G(生成器)不变训练D的。D的训练目标是正确区分fake/true,如果我们以1/0代表true/fake,则对第一项E因为输入采样自真实数据所以我们期望D(x)趋近于1,也就是第一项更大。同理第二项E输入采样自G生成数据,所以我们期望D(G(z))趋近于0更好,也就是说第二项又是更大。所以是这一部分是期望训练使得整体更大了,也就是maxD的含义了。
第二部分保持D不变,训练G,这个时候只有第二项E有用了,关键来了,因为我们要迷惑D,所以这时将label设置为1(我们知道是fake,所以才叫迷惑),希望D(G(z))输出接近于1,也就是这一项越小越好,这就是minG。当然判别器D哪有这么好糊弄,所以这个时候判别器就会产生比较大的误差,误差会更新G,那么G就会变得更好了,这次没有骗过你,只能下次更努力了。
Discriminator的损失函数
Generator的损失函数
在(近似)最优判别器下,最小化生成器的loss等价于最小化$P_r$与$P_g$之间的JS散度。
下图中可以发现,所有的loss都是由判别器产生的。如果没有D,G不知道自己生成的结果如何,便得不到权重更新。

1 | import torch |
1 | class Generator(nn.Module): |
2. 各式各样的GAN
2.1DCGAN
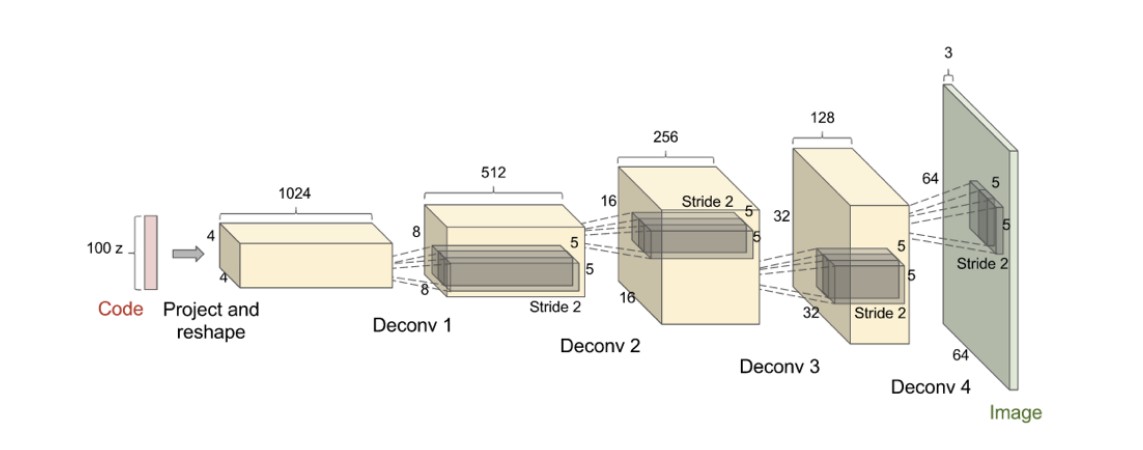
深度卷积生成对抗网络,在生成器中,对输入的一维向量不断进行转置卷积(上采样)最终生成对应的图像。在判别器中,则将输入的图像经过多层卷积最后经过sigmod函数进行二分类,判断这是原始数据图片还是生成器产生的图片。
1 | def weights_init(m): |
2.2 Conditional GAN
CGAN的目标函数与原始的并无太大不同,只不过加了一个限定条件。
1 | # G(z) |
结合介绍的两种,可以定义cDCNGAN模型(就是把Linear全连接层换为了ConvTranspose2d或Conv2d卷积层)。
2.3 Bidirectional GAN
讲述$BiGAN$的两篇论文分别为:
Donahue, Jeff, Philipp Krähenbühl, and Trevor Darrell. “Adversarial feature learning.” arXiv preprint arXiv:1605.09782 (2016).
Dumoulin, Vincent, et al. “Adversarially learned inference.” arXiv preprint arXiv:1606.00704 (2016).
网络架构
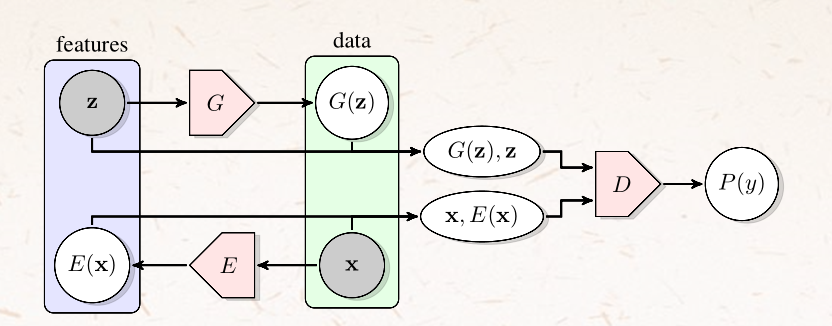
- 目标函数
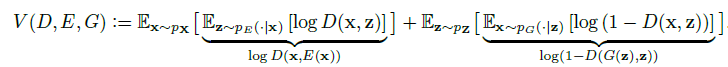
代码参考:https://github.com/fmu2/Wasserstein-BiGAN
2.4 WGAN
Arjovsky, M., Chintala, S., & Bottou, L. (2017). Wasserstein gan. arXiv preprint arXiv:1701.07875.(gradient clipping)
Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., & Courville, A. C. (2017). Improved training of wasserstein gans. In Advances in neural information processing systems (pp. 5767-5777).(gradient penalty)
参考:https://zhuanlan.zhihu.com/p/25071913(令人拍案叫绝的WGAN)。
$Wasserstein$距离也被称为$Earth mover’s$距离(推土机距离)。Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近。
我们可以构造一个含参数$w$、最后一层不是非线性激活层的判别器网络$f_w$,在限制$w$不超过某个范围的条件下,使得
尽可能取到最大,此时$L$就会近似真实分布与生成分布之间的Wasserstein距离(忽略常数倍数$K$)。

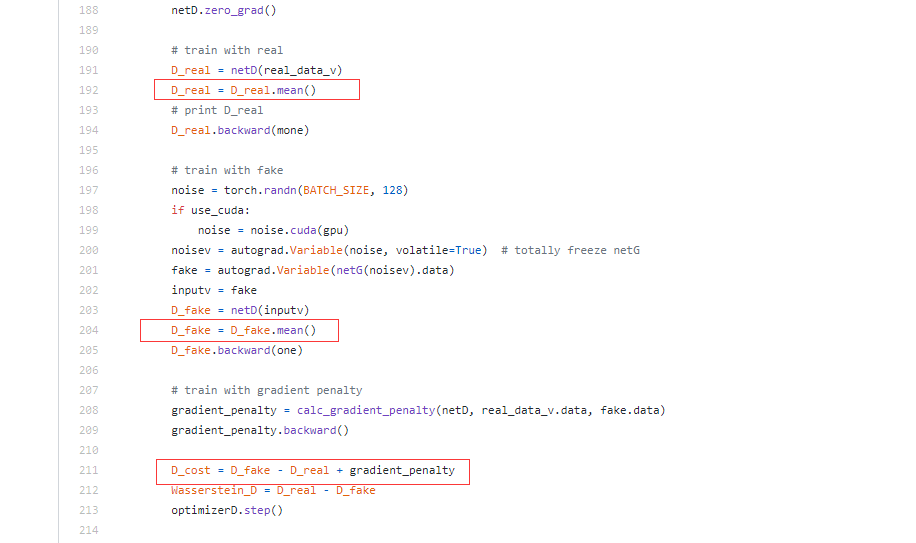
注:判别器要迭代训练多次。而生成器只训练一次。
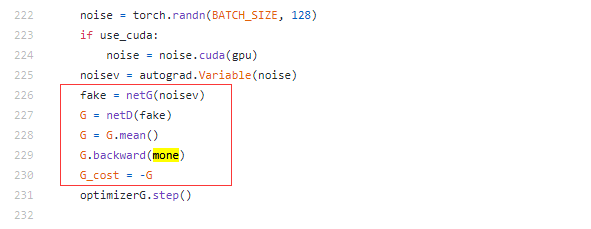
WGAN在原生的GAN做出的改进:
- G和D的损失函数不用对数
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
- D最后一层去掉$sigmod$二分类函数
- 采用gradient clipping和gradient penalty(改进)
原始GAN存在的问题:
- 判别器越好,生成器越容易产生梯度消失。
- 训练不稳定,容易导致$collapse mode$。
2.5 StackGAN由文本生成高分辨率图像
Zhang, Han, et al. “Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks.” Proceedings of the IEEE international conference on computer vision. 2017.
2.6 GANomaly异常检测
- 网络架构:
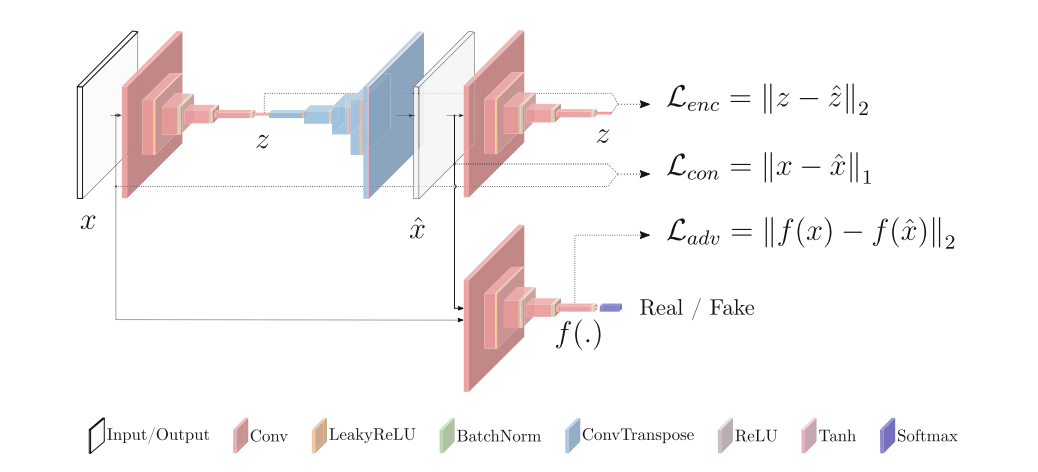
可以看出,模型包含两个encoder、一个decoder(相当于生成器)和一个判别器。模型划分为三个部分:第一部分为一个自动编码器,包含一个encoder($G_E$)、一个decoder($G_D$),这一部分被记为$G$;第二部分为一个encoder,记为$E$;第三部分为一个判别器网络,记为$D$。前两部分也被称为G-Net。
输入图片数据$x$经过一个encoder($G_E$)编码为向量$z$,decoder($G_D$)将向量$z$还原为原尺寸图像数据$\hat x$,另一个encoder($E$)将$\hat x$又编码为向量$\hat z$。将$x$和$\hat x$输入判别器网络($D$)判断图片是原始图片还是生成器生成的图片。
- 损失函数
损失函数共分为三部分,第一部分是$Enocder Loss$,衡量两个encoder编码向量的损失;第二部分是$Contextual Loss$,衡量原图像与生成器生成图像的损失,第三部分是$Adversial Loss$,是常规的GAN中判别网络的损失,这里采用的是二分类的交叉熵损失。
优化D-net,采用$Adversial Loss$。
优化G-net时,采用三部分损失函数的加权和。
- 异常检测
原理:由于训练输入的都是正常数据,第一个encoder学习到的是正常数据的分布,经过生成器的重建后再经过encoder编码差异不会很大,当输入异常数据时,encoder编码后会损失部分信息,经过生成器重建后再编码会与原来的数据差异很大,从而进行异常检测。
当异常得分$A$大于某一阈值时,模型就会判定该数据为异常数据。(异常检测并没有用到判别器)。
2.7 DiscoGAN关联分析
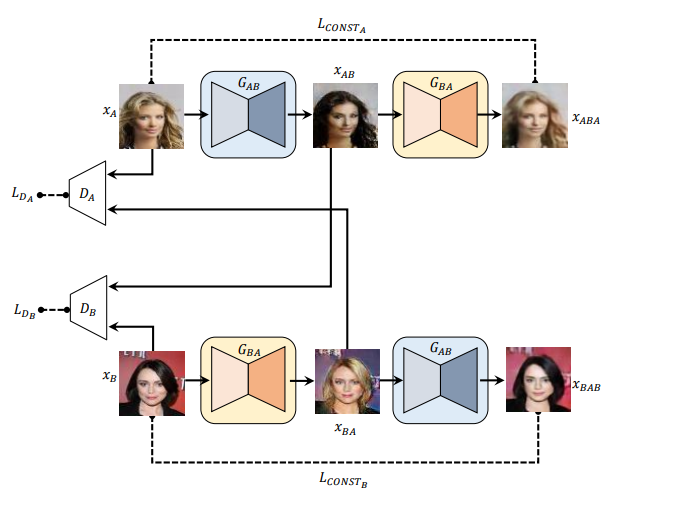
模型主要由两个生成器和两个判别器构成。
$G_{AB}$:输入A领域(domain)图片,生成B领域图片
$G_{BA}$:输入B领域图片,生成A领域图片
$D_A$:判别A领域原始图像和$G_{BA}$生成的A领域图像
$D_B$:判别B领域原始图像和$G_{AB}$生成的B领域图像