Dropout理解与实现
作用:
正则化的一种手段,训练过程中避免神经网络的过拟合。
在某一层中,随机使一部分神经元失活(输出为0),导致这部分神经元对下一层输入的贡献为0。
数学表达如下:
第$l + 1$层的输入:
$f$为激活函数。
若在该层使用dropout,则:
$r^{(l+1)}$是一个mask向量,只包含0、1,其中为0表示该神经元失活了。$\hat y^{(l+1)}$即作为下一层的输入。
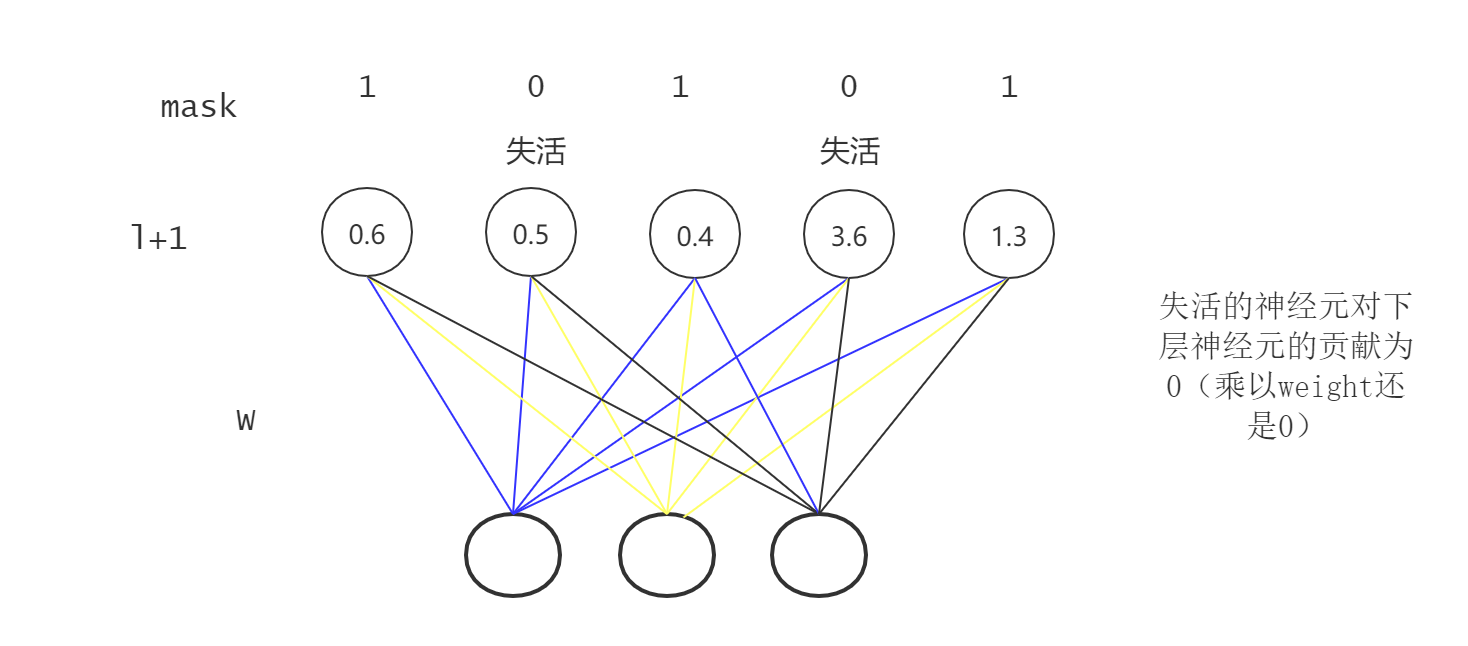
即等价于:
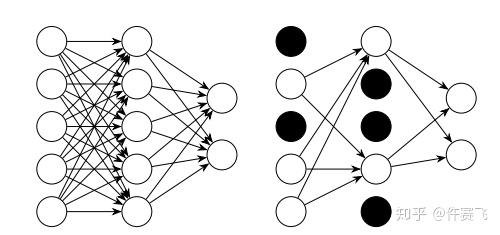
实现:
1
2
3
4
5
6
7
8
9'''
x: 输入
keep_prob: 留存概率
'''
def dropout(x, keep_prob):
mask = np.random.binomial(1, keep_prob, size=x.shape)
x *= mask
x = x / keep_prob # 对余下的神经元进行rescale
return x1
2
3
4
5
6
7
8
9
10
11
12
13
14def forward(x, W1, W2, W3, training=False):
z1 = np.dot(x, W1)
y1 = np.tanh(z1)
z2 = np.dot(y1, W2)
y2 = np.tanh(z2)
# Dropout in layer 2
if training:
m2 = np.random.binomial(1, 0.5, size=z2.shape) # 生成mask
else:
m2 = 0.5 # 训练中没有rescale,测试时需要平衡训练中失活的神经元数量
y2 *= m2 # 乘以mask,为0即代表失活
z3 = np.dot(y2, W3)
y3 = z3 # linear output
return y1, y2, y3, m21
2
3
4
5
6
7
8
9
10
11def forward(x, W1, W2, W3, training=False):
z1 = np.dot(x, W1)
y1 = np.tanh(z1)
z2 = np.dot(y1, W2)
y2 = np.tanh(z2)
# Dropout in layer 2
if training:
y2 = dropout(y2,0.5) # 训练阶段已经进行了rescale
z3 = np.dot(y2, W3)
y3 = z3 # linear output
return y1, y2, y3, m2注意:
测试中不需要dropout。dropout一般用于全连接层之前,对卷积层的效果一般。