Pytorch学习笔记之卷积神经网络
1 模型构建
在pytorch中,我们构建的模型都继承自torch.nn.Module这个类,并且要重写其forward方法。
1 | import torch.nn as nn |
总的来说,要经过 3 个步骤:
继承
nn.Moudle在
__init__(self)方法中定义神经网络中的layer作为类的属性- 实现
forward()方法。
tips:一个多通道卷积与feature maps作卷积,结果是一个数值(每个通道卷积最后加起来),因此,output_channels的数量取决于卷积核的数量。每一层卷积的参数 = channels * kernel_nums * size。
在定义好模型结构后,就可以输入训练集进行迭代训练直至收敛。
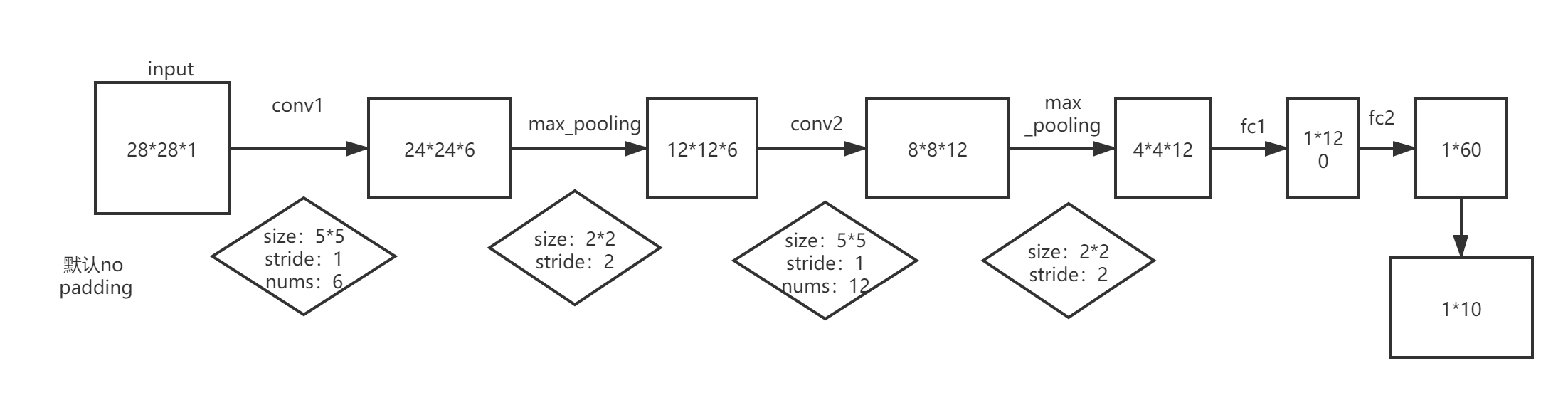
上述网络结构中,feature maps尺寸变化如下:
feature_map变换公式:
- 图片大小 $W$
- 卷积核
filter大小 $F$ - 步长
stride大小 $S$ - 填充
padding大小 $P$ max_pooling层 核大小 $f$max_pooling层步长stride$s$
经过卷积输出大小 $N$ 有:
再经过max_pooling ,最终大小 $M$ ,有:
注:nn.Conv2d输出维度:[batch_size, channels, width, height]
2 训练你的模型
训练流程:
1 | 1. Get batch from the training set. |
batch:每次输入神经网络中的数据集数量。
epoch:遍历完整个数据集称之为一个epoch。
整个流程代码如下:
1 | import torch |
最后可以看出,在训练集上的准确率为 $88\%$ 左右。
输出如下:
1 | epoch 0 total_correct: 51138 loss: 238.7455054372549 |
在测试集上的表现如何?
1 | test_set = torchvision.datasets.FashionMNIST( |
在测试集上的准确率为 $86.31\%$。仍然有很大改善空间。
下面观察以下经过conv1、conv2后的feature maps。(没有经过最大池化)
1 | sets = iter(train_loader) |

3 记点其他的知识
3.1 Batch Normalization
在Pytorch中,位于torch.nn包下。[ https://pytorch.org/docs/stable/nn.html#batchnorm2d ]
提出原因:解决梯度消失问题, 加速训练收敛过程 。
原理:将隐层的输入分布变为均值为 $0$ ,方差为 $1$ 的正态分布。
设$X = \{x_1,x_2,…,x_m\}$表示$X$的维度。$m$ 代表 $batch-size$.
计算样本每个维度均值:
计算样本每个维度的方差:
其中,$\gamma$、$\beta$ 是通过学习得到的。
如何操作:即将input与weight matrix相乘后,再作为激活函数的输入。在CNN中,是做完卷积操作后,激活函数之前。在训练时,均值、方差都是训练时batch的统计数据,可以记下然后做加权平均得到测试时使用的均值和方差,在测试时使用。
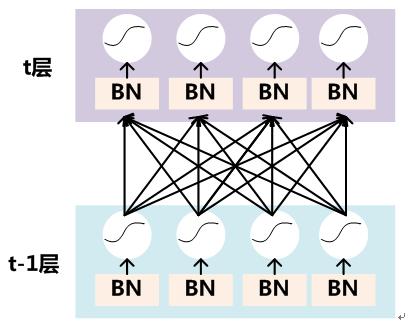

进一步的理解:
在原论文3.2节,作者提到 $BN$ 通常加入到非线性单元(激活函数)之前,对 $Wu + b$ 进行normalizing,而不是 $u$,作者是这样解释的:$u$ 可能是上一个非线性单元的输出,非线性单元的输出分布形状会在训练过程中变化,归一化无法消除他的方差偏移。
而对于 $Wu+b$ (线性变换,卷积操作也是线性变换)这种变换的输出一般是一个对称,非稀疏的一个分布,更加类似高斯分布,对他们进行归一化会产生更加稳定的分布。
看一下 $W u + b$ 经过$BN$后,参数 $b$ 的变化:
可以看到参数$b$最后被消掉了,可有可无。因此可以表示为:
We could have also normalized the layer inputs u, but since u is likely the output of another nonlinearity, the shape of its distribution is likely to change during training, and constraining its first and second moments would not eliminate the co-variate shift.
In contrast, Wu + b is more likely to have a symmetric, non-sparse distribution, that is “more Gaussian”; normalizing it is likely to produce activations with a stable distribution.
经过卷积后怎么 BN
通常经过卷积操作后,会产生多个channel。将每个channel视为一个维度,统计channel内所有样本的均值和方差,这样每个channel对应一对参数$\gamma,\beta$。比如:[batch_size,channel,width,height],每个channel内,batch_size * width * height的均值和方差。$\gamma$
3.2 Dropout
在Pytorch中,位于torch.nn包下。
提出原因:解决过拟合问题。
3.3 卷积数学定义
离散卷积
连续卷积
事实上,我们在二维卷积的时候,使用的卷积核是经过反转后的,为了方便计算。在进行一维卷积时,也需要对核进行反转(左右反转)。
参考:https://www.cnblogs.com/itmorn/p/11177439.html
3.4 Attention 机制
传统 Encoder-Decoder 模型:
在传统的模型中, 我们仅使用 Encoder 的最后一个隐状态作为 Decoder 的初始隐状态,Encoder 最后的隐状态被称为context vector向量,因为他对整个输入的 sentence 做了一个编码。在之后的 Decoder 模型中,Decoder初始input为SOS(start of string) token,初始隐状态为这个 context vector,然后接受上一次的output作为input迭代完成训练。
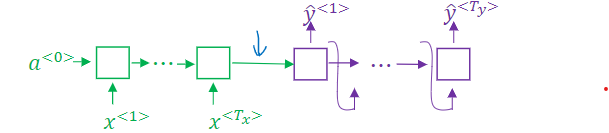
加入了 Attention 机制的 Encoder-Decoder 模型:
标准$seq2seq$模型通常无法准确处理长输入序列,因为只有编码器的最后一个隐藏状态被用作解码器的上下文向量。 另一方面,注意力机制在解码过程中保留并利用了输入序列的所有隐藏状态(context vector),因此直接解决了此问题。 它通过在解码器输出的每个时间步长到所有编码器隐藏状态之间创建唯一的映射来实现此目的。 这意味着,对于解码器产生的每个输出,它都可以访问整个输入序列,并且可以从该序列中有选择地选择特定元素以产生输出。 相对于传统 LSTM 记忆网络处理长度较长的序列,加入 Attention 后参数减少。
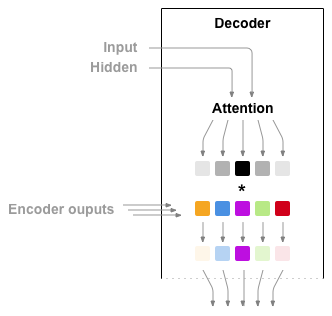
Attention 机制分为不同的种类,但总的来说大概分为以下几步:
1 | 1. Calculating Alignment Scores |
具体实现参考:
https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html
https://blog.floydhub.com/attention-mechanism/

下面介绍NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE论文中提到的 Attention 机制。
首先将序列经过 Encoder 模型,产生所有隐状态$H_{Encoder}$
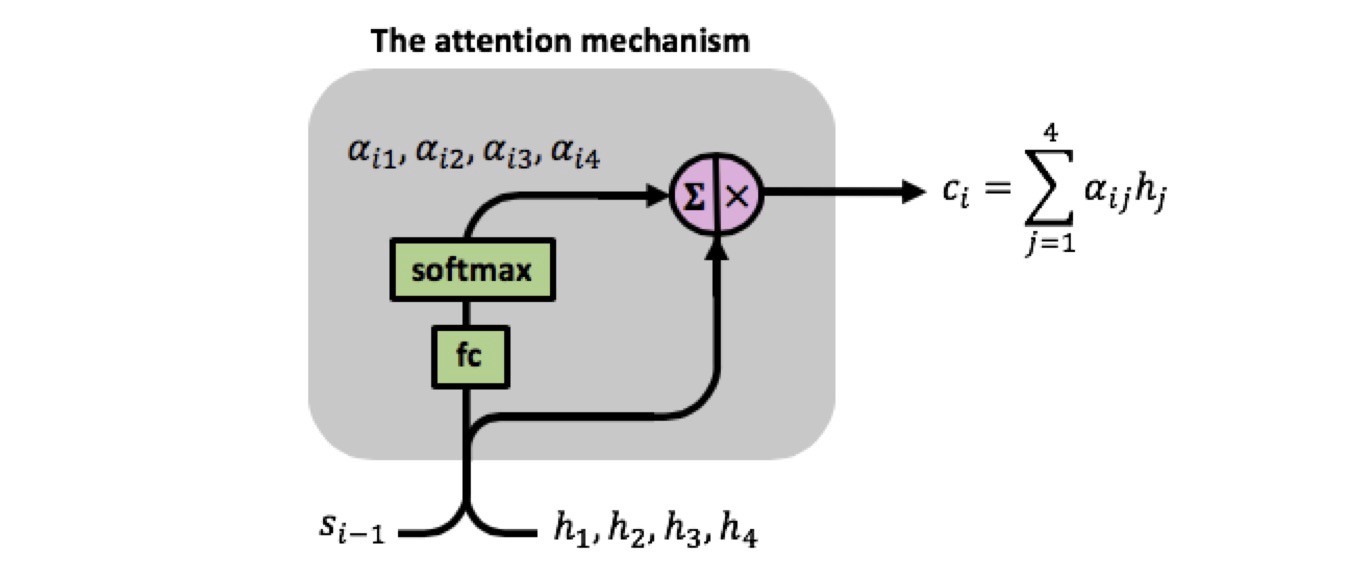
计算 Alignment Scores:
在 Decoder 模型中,时间 $i$ 对应的前一个隐状态为$s_{i-1}$,
表示不同$h_j$对$s_{i}$的影响程度。即将 $s_{i-1}$ 与每一个 Encoder 的隐状态经过一个函数得到输出,这个函数的参数通过学习得到。
$soft\max$归一化,得到 attention weights
计算 context vector:
注意:此时$c_i$仍是一个多维向量,相加的时候是各个维度分别相加。
将 context vector 与$t-1$的 output 作为输入( _concatenated_ ),与$s_{i-1}$传入 decoder 模型中得到输出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import numpy as np
# 所有encoder隐状态 共有3个隐态,维度为4
hidden_states = np.array([
[1,2,3,4],
[2,3,5,7],
[0,-1,3,6]
])
# 得出的attention权重
weights = np.array([[0.6,0.3,0.1]])
# weights和hidden_states 相乘
np.dot(weights,hidden_states)
#各个维度相加得到context_vector
array([[1.2, 2. , 3.6, 5.1]])
1 | class BahdanauDecoder(nn.Module): |
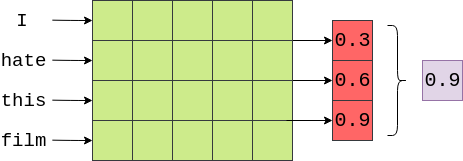
4. 卷积网络之电影评论情感分类
参考:https://github.com/bentrevett/pytorch-sentiment-analysis
采用IMDB数据集,使用glove.6B.100d预训练好的词向量。label总共有两类:消极评价:neg,积极评价:pos。
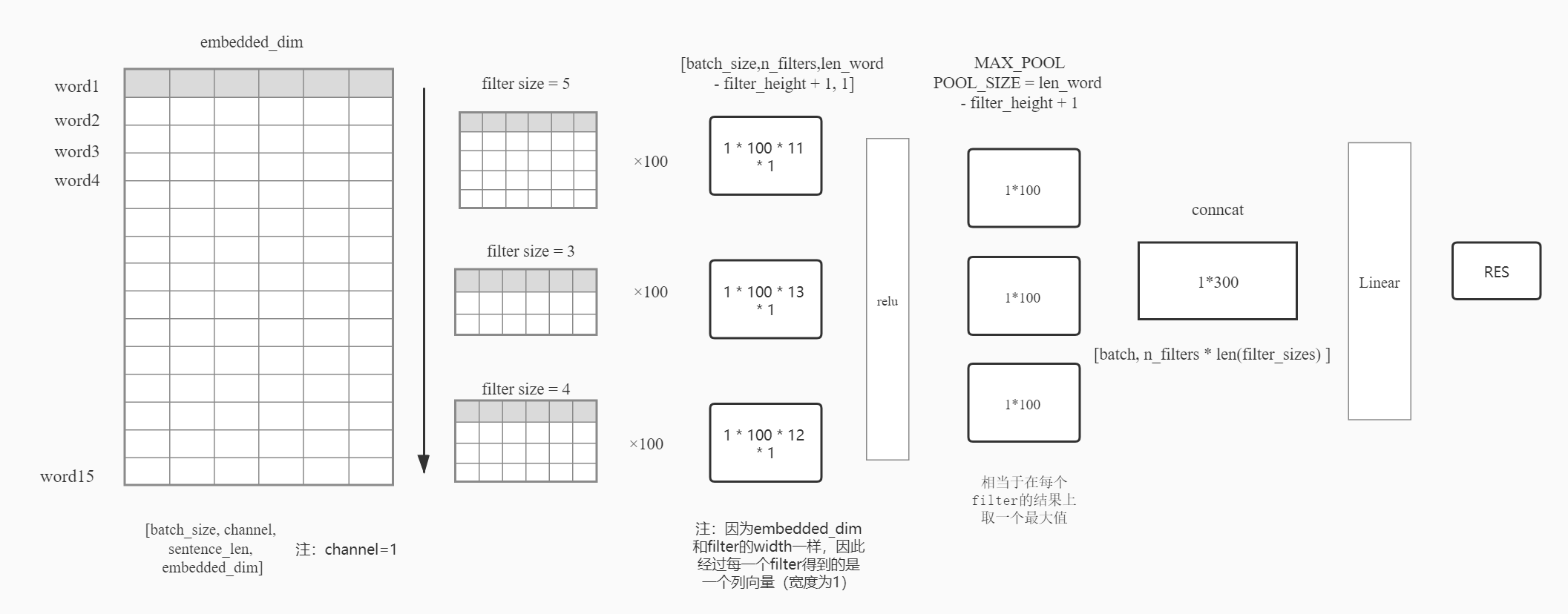
使用卷积网络用来扫描词向量组成的矩阵,即使用过滤器(filters)扫描embedding矩阵,这里介绍的模型使用三个大小不同的filter,每个filter共100个,filter的宽度和embedding_dim相同,高度分为3、4、5,即filter每次扫描的单词个数分别为3、4、5,filter每次移动1个单词距离。最后的向量shape为[lenth_of_the_word - height_of_the_filter + 1, 1]。将经过不同filter后的向量拼接起来然后经过全连接得到最终的预测结果。