Spark学习笔记
1. 概述
Spark是一个计算框架,可以整合Hadoop的HDFS和其他资源调度器s(YARN、Mesos、K8s)。
2. Spark安装
2.1 Local模式
2.2 Standalone模式
2.3 Yarn模式
3. Spark设计与运行流程
3.1 Spark基本概念
Driver、Master、Worker、Executor、RDD、DAG、Application、Job、Stage、Tasks、Partition
一个Application可以划分为多个Job,当遇到一个Action操作后就会触发一个Job的计算;一个Job可划分为多个Stage,出现shuffle就划分一个阶段(ShuffleMapStage);一个Stage包含多个Partition,一个Partition对应一个Task,因此一个Stage就是一个TaskSet。
划分Job依据:
注:有的Transformation算子也会被划分为一个Job。
application -> jobs -> stage -> tasks。
3.2 Spark架构

3.3 Spark运行流程
宽依赖:发生了Shuffle,就是宽依赖(不可以并行处理)一个父RDD对应多个儿子RDD分区,这些所有儿子RDD在没有得到父RDD分区数据时,不能干别的,只能等待。比如groupByKey操作。Shuffle会引发写磁盘操作(spill to disk)。
窄依赖: 一个父RDD对应一个儿子RDD,或多个父RDD对应一个儿子RDD。可以进行流水线优化(不发生磁盘写操作),对其中一个父RDD传过来的数据就可以处理,儿子RDD无需等待所有父RDD数据到达。filter、map操作。
Spark的DAGScheduler会根据程序生成的DAG确定宽依赖、窄依赖,进而划分作业到不同的阶段。
3.4 Scheduler模块源码分析
Spark的任务调度是从DAG切割开始,主要是由DAGScheduler来完成。当遇到一个Action操作后就会触发一个Job的计算,并交给DAGScheduler来提交,下图是涉及到Job提交的相关方法调用流程图。
Stage的调度
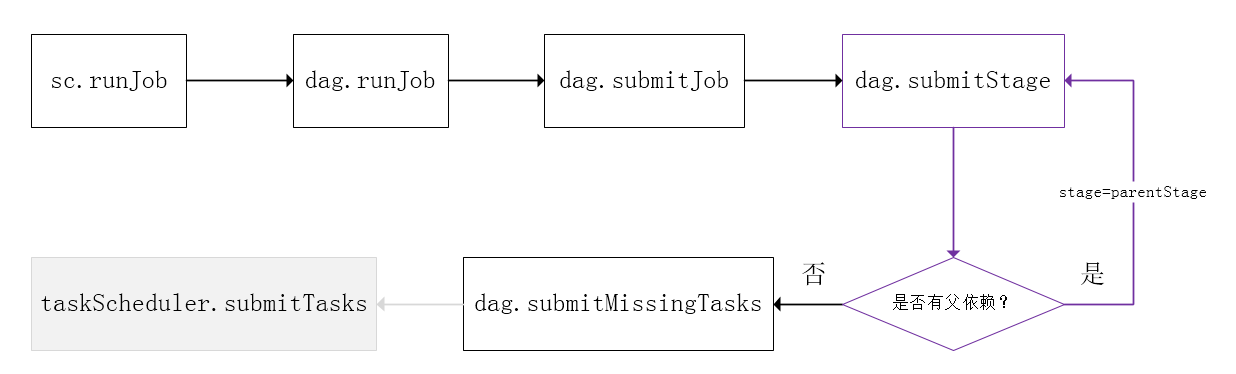
Task级的调度
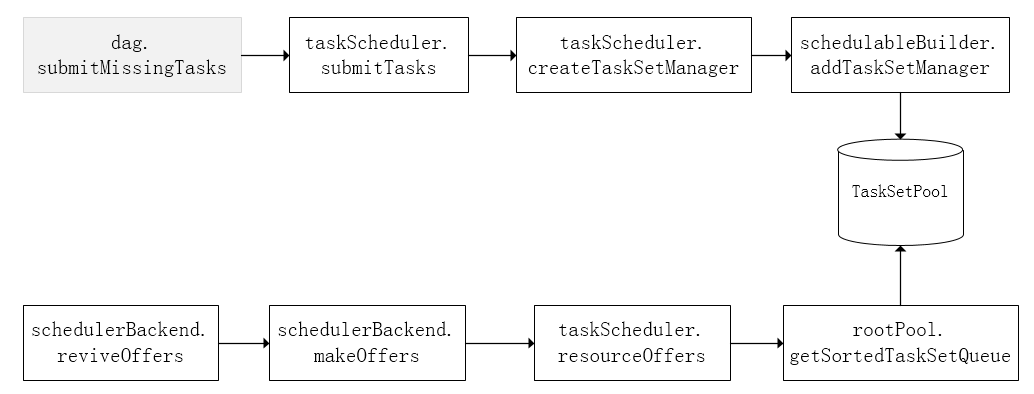
DAGScheduler将Stage打包到TaskSet交给TaskScheduler,TaskScheduler会将其封装为TaskSetManager加入到调度队列中,TaskSetManager负责监控管理同一个Stage中的Tasks,TaskScheduler就是以TaskSetManager为单元来调度任务。
TaskScheduler支持两种调度策略,一种是FIFO,也是默认的调度策略,另一种是FAIR。
从调度队列中拿到TaskSetManager后,那么接下来的工作就是TaskSetManager按照一定的规则一个个取出Task给TaskScheduler,TaskScheduler再交给SchedulerBackend去发到Executor上执行。前面也提到,TaskSetManager封装了一个Stage的所有Task,并负责管理调度这些Task。(http://sharkdtu.com/posts/spark-scheduler.htm)
3.5.1 单机模式
独立集群(stand alone)模式:该模式,Spark既负责计算,也负责资源的调度。有Master结点和Slaves结点,Master负责资源调度,Slaves负责执行计算(Executor)。
Yarn模式:Yarn负责资源调度,Spark负责计算。
yarn-client:driver位于提交job的机器上,实时展示job运行情况

执行流程:
1.客户端提交一个Application,在客户端启动一个Driver进程。
2.Driver进程会向RS(ResourceManager)发送请求,启动AM(ApplicationMaster)。
3.RS收到请求,随机选择一台NM(NodeManager)启动AM。这里的NM相当于Standalone中的Worker节点。
4.AM启动后,会向RS请求一批container资源,用于启动Executor。
5.RS会找到一批NM返回给AM,用于启动Executor。AM会向NM发送命令启动Executor。
6.Executor启动后,会反向注册给Driver,Driver发送task到Executor,执行情况和结果返回给Driver端。
yarn-cluster:driver位于集群中某个结点。
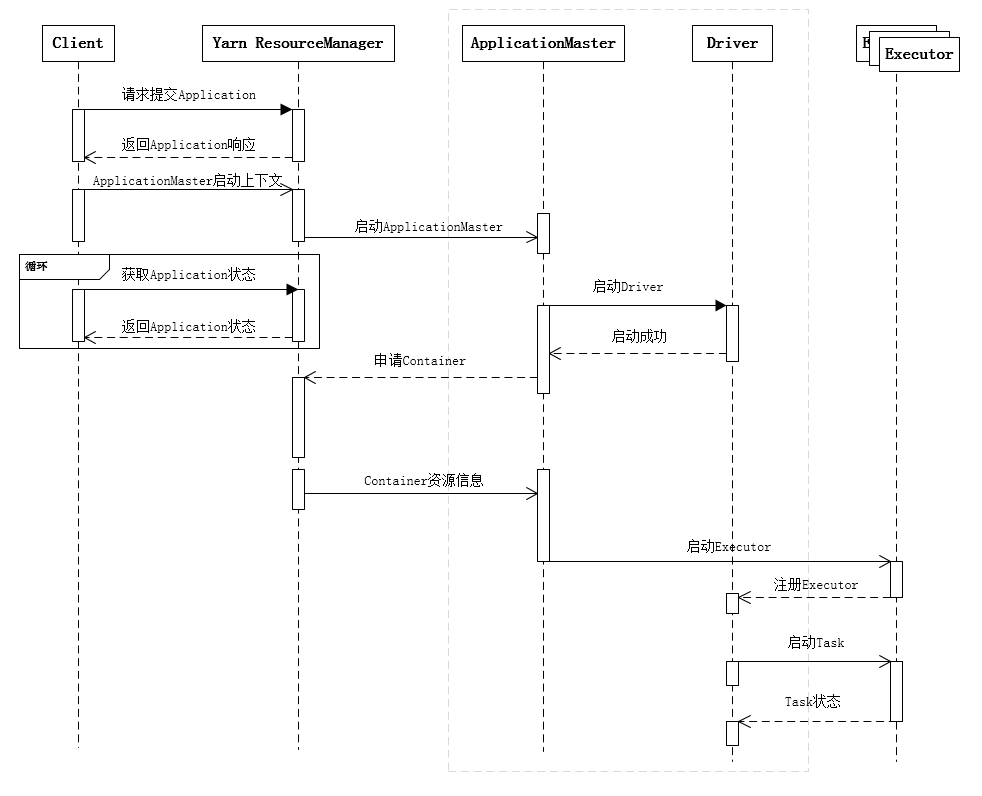
执行流程:
1.客户机提交Application应用程序,发送请求到RS(ResourceManager),请求启动AM(ApplicationMaster)。
2.RS收到请求后随机在一台NM(NodeManager)上启动AM,
3.AM启动,AM拿到客户机提交的程序的代码,运行Driver进程;AM发送请求到RS,请求一批container用于启动Executor。
3.RS返回一批NM节点给AM,。
4.AM连接到NM,发送请求到NM在Container启动Executor。
5.Executor反向注册到AM所在的节点的Driver。Driver发送task到Executor。
NodeManager会向AM报告container资源情况,而Executor会向Driver报告计算情况。AM一个负责资源调度、一个负责计算,在cluster模式时。
3.6 RDD编程
Resilient Distributed Dataset(弹性分布式数据集)是多个分区(Partition)的集合。一个RDD对象包含一个或多个Partition。
RDD操作(算子)类型:transformations和actions,前者不会进行计算(只生成新的RDD对象),后者会引起真正的计算(runJob进而划分阶段提交task,driver分发task给Executor去计算)。
RDD创建:
1.集合中创建:parallelize/makeRDD
2.外部存储:textFile
3.其他RDD转换
1 | >val rdd = sc.makeRDD(List("a_b","c_d","e_f")) |
mapPartition、foreachPartiton 容易造成内存溢出(OOM)。
collect会把所有数据拉取到Driver结点上。
广播变量
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个Spark操作使用,减少网络传输开销,优化性能。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,甚至是机器学习算法中的一个很大的特征向量,广播变量用起来都很顺手。 在多个并行操作中使用同一个变量,但是 Spark会为每个任务分别发送。
1 | scala> val broadcastVar = sc.broadcast(Array(1, 2, 3)) |
使用广播变量的过程如下:
(1) 通过对一个类型 T 的对象调用 SparkContext.broadcast 创建出一个 Broadcast[T] 对象。 任何可序列化的类型都可以这么实现。
(2) 通过 value 属性访问该对象的值(在 Java 中为 value() 方法)。
(3) 变量只会被发到各个节点一次,应作为只读值处理(修改这个值不会影响到别的节点)。
多文件排序
1 | import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} |
找出多个文件中的最大值和最小值
1 | import org.apache.spark.{SparkConf, SparkContext} |
| Transformation | Meaning |
|---|---|
| map(func) | Return a new distributed dataset formed by passing each element of the source through a function func. |
| filter(func) | Return a new dataset formed by selecting those elements of the source on which func returns true. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). |
| mapPartitions(func) | Similar to map, but runs separately on each partition (block) of the RDD, so func must be of type Iterator |
| mapPartitionsWithIndex(func) | Similar to mapPartitions, but also provides func with an integer value representing the index of the partition, so func must be of type (Int, Iterator |
| sample(withReplacement, fraction, seed) | Sample a fraction fraction of the data, with or without replacement, using a given random number generator seed. |
| distinct([numPartitions])) | Return a new dataset that contains the distinct elements of the source dataset. |
| groupByKey([numPartitions]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, IterablereduceByKey or aggregateByKey will yield much better performance. Note: By default, the level of parallelism in the output depends on the number of partitions of the parent RDD. You can pass an optional numPartitions argument to set a different number of tasks. |
| reduceByKey(func, [numPartitions]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function func, which must be of type (V,V) => V. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. |
| sortByKey([ascending], [numPartitions]) | When called on a dataset of (K, V) pairs where K implements Ordered, returns a dataset of (K, V) pairs sorted by keys in ascending or descending order, as specified in the boolean ascending argument. |
| join(otherDataset, [numPartitions]) | When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all pairs of elements for each key. Outer joins are supported through leftOuterJoin, rightOuterJoin, and fullOuterJoin. |
| repartition(numPartitions) | Reshuffle the data in the RDD randomly to create either more or fewer partitions and balance it across them. This always shuffles all data over the network. |
| Action | Meaning |
|---|---|
| reduce(func) | Aggregate the elements of the dataset using a function func (which takes two arguments and returns one). The function should be commutative and associative so that it can be computed correctly in parallel. |
| collect() | Return all the elements of the dataset as an array at the driver program. This is usually useful after a filter or other operation that returns a sufficiently small subset of the data. |
| first() | Return the first element of the dataset (similar to take(1)). |
| take(n) | Return an array with the first n elements of the dataset. |
| saveAsTextFile(path) | Write the elements of the dataset as a text file (or set of text files) in a given directory in the local filesystem, HDFS or any other Hadoop-supported file system. Spark will call toString on each element to convert it to a line of text in the file. |
| countByKey() | Only available on RDDs of type (K, V). Returns a hashmap of (K, Int) pairs with the count of each key. |
| foreach(func) | Run a function func on each element of the dataset. This is usually done for side effects such as updating an Accumulator or interacting with external storage systems. Note: modifying variables other than Accumulators outside of the foreach() may result in undefined behavior. See Understanding closures for more details. |
| count() | Return the number of elements in the dataset. |