Word Embedding之skip-gram
1.Word Embedding
词的分布式表示大致可以分为基于矩阵、基于聚类、基于神经网络等表示方法。1986年,Hinton就提出了分布式表示想法;2003年,Bengio也发表论文表达了相关想法。基于神经网络的分布式表示一般称为词向量、词嵌入(word embedding)、分布式表示( distributed representation)。词嵌入就是指将词汇映射到实数向量空间的概念(模型)。神经网络词向量表示技术通过神经网络技术对上下文,以及上下文与目标词之间的关系进行建模。神经网络模型有skip-gram和Continous Bag of Words Model(CBOW)模型。
word2vec是谷歌2013年提出一种word embedding 的工具或者算法集合,在word2vec中给出了这skip-gram和cbow模型的训练和生成方式。
2. skip gram
由于词为字符串,而输入到网络中的是向量,因此传统常用one-hot表示,把每个词表示为一个很长的向量,但这个向量是非常稀疏的,且向量不包含其他含义,因此,word embedding就是找到n个属性来表示这个词,这种表示方法不仅可以大大降低维度,而且可以通过向量计算两个词的“距离”。比如少年、男人、少女这几个词,就可以选择年龄、性别这两个属性来描述。
skip-gram其实就是训练一个小型神经网络,将单词映射到向量空间只是其中的一步。该神经网络最后的输出,其实是词库中各个单词出现在给定输入单词附近的概率——给定中心词,预测附近单词。
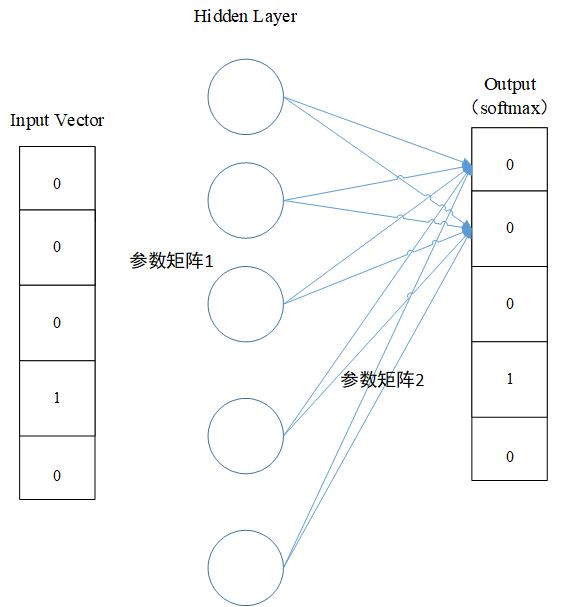
整体网络架构为三层(输入层、隐藏层、输出层)。假设有一个词汇量为10000的词库。
输入层为单词的one-hot表示向量(10000维),隐藏层没有激活函数,输出层采用softmax函数,输出一个概率分布(10000维向量),表示词汇表各个单词在输入词附近(nearby)的概率。隐藏层的神经元数量就是单词映射到实数空间属性个数。输入层和隐藏层之间的权重就是我们需要的,也就是作为词汇最后的映射空间。
网络模型:
输入:$word_{1\times v}、target$
参数:$W_{v \times N}$、$W_{N\times V}$
输出:$P_{1\times V}$
训练过程:
训练数据的产生
训练数据采用滑动窗口,在一个句子中滑动,窗口大小是一个超参数。比如:

中心单词not,窗口大小为2。此次滑动产生的数据为:
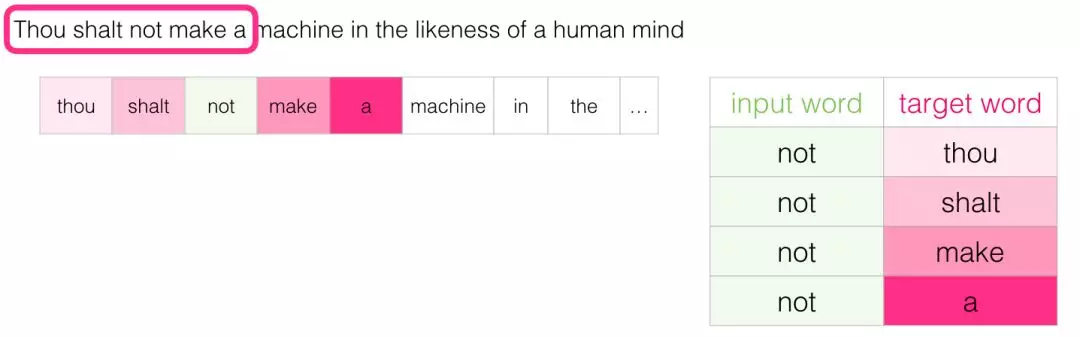
以此类推。

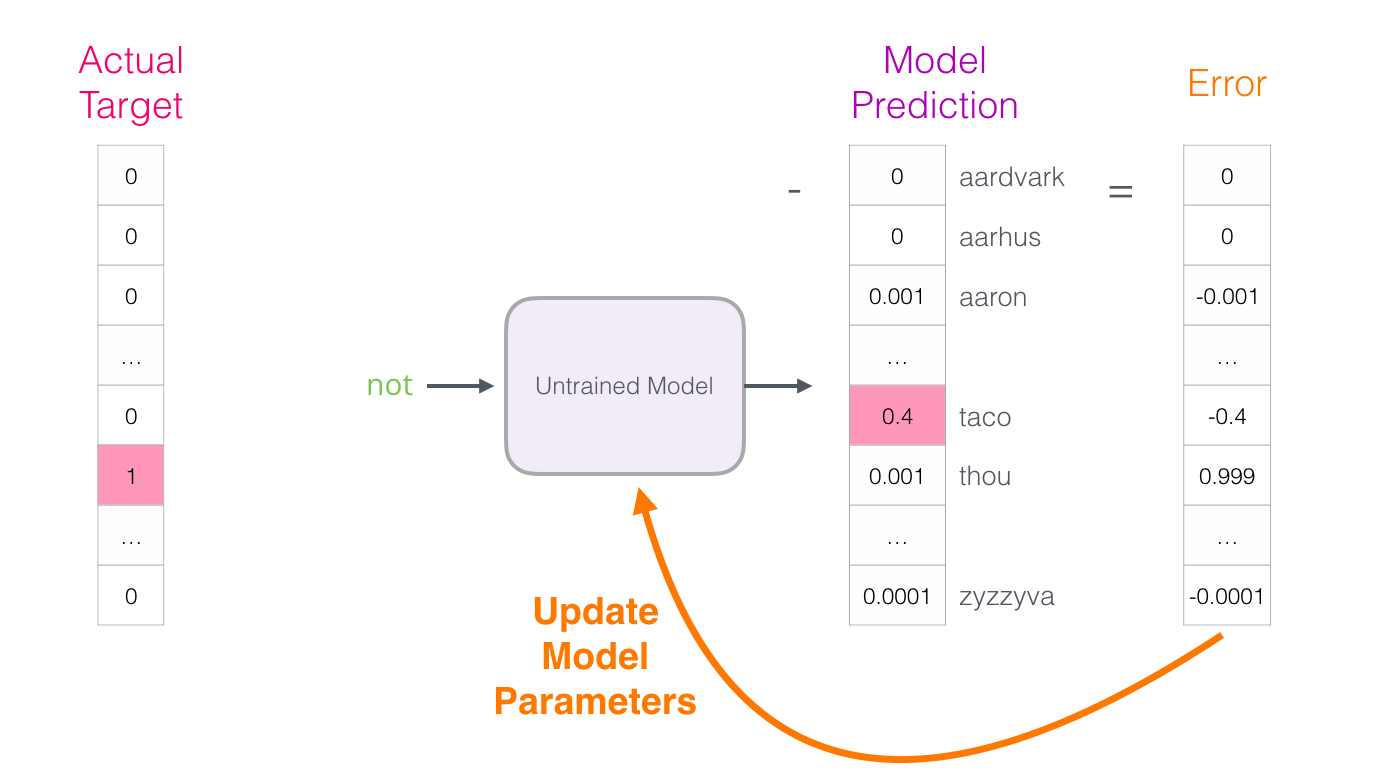
训练
将产生的数据输入网络,计算输出层产生的概率向量和target word的one-hot向量的loss,然后反向传播更新参数矩阵。
3. Negative Sampling和Hierarchical softmax
在2013年初word2vec论文发表后,10月谷歌又发了一篇文章,提出了negative sampling和Hierarchical softmax,两种方法都可以加速网络的收敛过程和训练速度。
3.1 Negative Sampling
以上过程有助于了解网络是如何运作的,但是该网络采用softmax激活函数,每次训练都要计算隐藏层向量和参数矩阵2相乘并反向计算梯度,训练成本较高,因此word2vec中使用了基于负例采样(negative sampling)的skip gram以此来降低计算成本。具体就是将softmax函数转化为逻辑回归(二分类),将预测概率问题转为一个二分类问题,输出target是否为input的nearby。负采样就是在数据集中加入target不是input的nearby的样本。
采用negative sampling的skip-gram大致训练过程如下:
选择与input word相邻的单词作为output word,target为1,表示相邻,再随机选择5-20个不相邻单词作为output word,target为0,将input word输入到网络中经过隐藏层得到embedding后的vector,与output word对应的weight(参数矩阵2的某一列)点乘得到向量积,再经过sigmod函数,得到一个分数,与target的差即为loss,反向传播然后更新参数矩阵1(Embedding矩阵)中input word对应的weight,和参数矩阵2(Context矩阵)中output word对应的weight,这样每次训练只需要更新部分权重(负例对应的Context权重、input word对应的Embedding权重),而非整个权重,从而加快收敛过程。

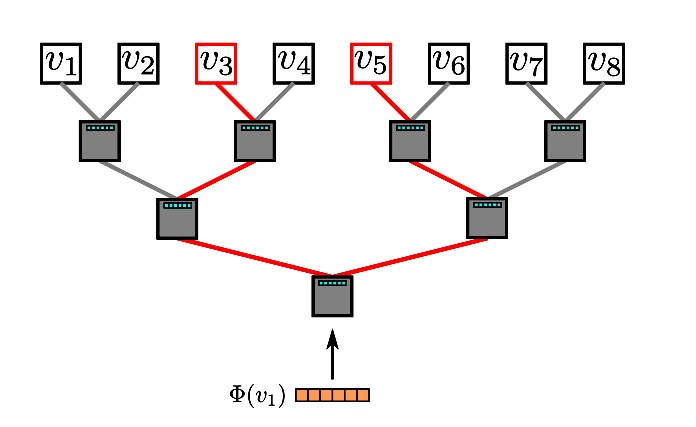
3.2 Hierarchical softmax
Hierarchical softmax利用词汇建立一棵哈夫曼树,树中每个结点除了包含指向左右子树结点的指针,还有对应结点的权重向量。树中每个节点都相当于一个二分类模型,计算左右结点的概率,最终到达叶子节点。
4. 后续
word2vec不仅可以用来处理nlp问题,而且基本已经成为深度学习中的一个基本模型。
参考文献
强烈推荐!!!
[1]. http://jalammar.github.io/illustrated-word2vec/
[3]. http://mccormickml.com/2017/01/11/word2vec-tutorial-part-2-negative-sampling/