信用卡虚假交易数据检测
测试网站:https://www.lintcode.com/ai/creditcard_fraud/overview
0. 背景介绍
信用卡虚假交易即指该交易有涉嫌非法套现的行为,即用户在商户刷卡后,商户不提供用户消费品而是把消费的钱通过现金的方式返还给用户同时抽取一部分费用作为佣金,虚假交易检测即给定某一交易数据,判定该交易是否是虚假交易。
1. 数据探索
数据集为2013年9月里某两天欧元区的信用卡交易记录。在这两天中共有284807笔交易,其中的492笔是欺诈。把欺诈交易的类(class) 认为是1,非欺诈交易的类认为是0。给定数据集中,正常数据有22万余条,虚假数据只有400多条,可见训练数据严重失衡,需要通过采取一些措施解决这种不平衡。
1.1 数据属性
数据集里面有从PCA转换得到的28个features。之所以进行了PCA转换是因为不能把原始的消费者信用卡记录暴露给公众,这样触犯了用户的隐私。所以做PCA转换处理。可以简单理解为加密。
Features V1, V2, …, V28都是经过PCA转换后获得的features。没有被PCA转换的,保留了原始数据是”Time”和”Amount”。”Time”记录了每笔交易和第一笔交易(Time属性为0)之间的时间间隔,以秒为单位。”Amount”是交易数额。”Class”就是这笔交易的最终分类。
1.2 数据分布
导入数据。
1 | import pandas as pd |
我们首先统计在不同的时间间隔内正常交易的数量和虚假交易的数量是怎样的。
1 | f, (ax1, ax2) = plt.subplots(2, 1, sharex=True, figsize=(12, 4)) |
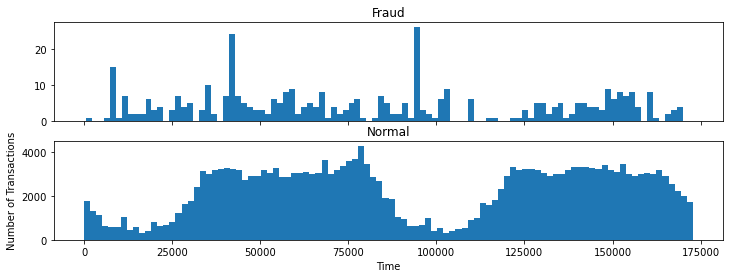
可以看到,正常交易有一个明显的周期性,而虚假交易呈现一个均匀分布的趋势。
我们再统计不同交易金额的交易数量。
1 | f, (ax1, ax2) = plt.subplots(2, 1, sharex=True, figsize=(12, 4)) |
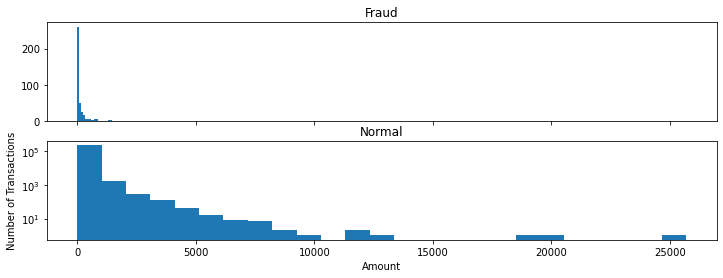
可以看到,正常交易的交易金额比虚假交易金额要大,虚假交易的交易金额最大不超过2500。
2. 数据清洗
2.1 数据标准化
首先将“Time”、“Amount”这两列标准化,需要注意的是,训练数据标准化意味着测试数据集也需要标准化,要将二者置于同一尺度下才能较好的预测结果。注意:标准化的时候注意防止数据泄露!
- 先将数据划分为训练集和测试集
1 | from sklearn.model_selection import train_test_split |
- 数据标准化
1 | from sklearn.preprocessing import StandardScaler |
2.2 解决样本不平衡问题
对于样本类别数量极不平衡通常有过采样(over-sampling)、欠采样(under-sampling)两种方法。过采样用于扩增数据集,而欠采样用于减小数据集。
本例中,由于预测的数据在5万条,给定的训练数据中异常数据只有400条左右,如果做欠采样,需要使得正常数据与虚假数据数量相同,那么训练模型的数据大约为900条,这样训练出的模型大概率是欠拟合的,无法应对大规模测试集的情况。
因此,采用SMOTE算法对数据集进行过采样,使得虚假交易数据与正常交易数据相同。
1 | from imblearn.over_sampling import SMOTE |
3. 模型选择
模型尝试了LR、决策树、随机森林、XGBClassifier。最终随机森林在数据集上取得的分数最高为0.87。
1 | from sklearn.ensemble import RandomForestClassifier |
由于随机的原因分数误差在0.1上下。