Python一行代码实现滑动窗口
1 | # 数据的加载 |
版本:8.0
查看会话当前使用的哪个数据库:
1 | select database(); |
设置关闭自动提交事务:
1 | set autocommit = 0; |
隔离级别总共有四种:
查看当前会话事务的隔离级别:
1 | select @@transaction_isolation; |
查看数据库的隔离级别:
1 | select @@global.transaction_isolation; |
1 | mysql> select @@global.transaction_isolation; |
可见innoDB默认的是可重复读这一隔离级别。可重复读可以避免”不可重读“(innoDB在PR级别通过MVCC解决了幻读这一现象)
排它锁(Exclusive),又称为X 锁,写锁。
共享锁(Shared),又称为S 锁,读锁。
读写锁之间有以下的关系:
读写锁之间的关系可以概括为:允许多个事务一起读,读写互斥!
但加行锁并不可以解决”幻读“这一现象,因为行锁无法对后insert的数据加锁。幻读指的是当某个事务在读取某个范围内的记录时,另外一个事务又在该范围内插入了新行,当之前的事务再次读取该范围的记录时,会产生幻行。解决幻读要么序列化,要么加表锁。
首先了解两个概念:
select * from table_1 for update读取数据库最新的内容Mysql中主要通过MVCC来保证可重复读,和select级别的幻读。注意:当其他事务进行提交后,本事务要对提交的数据进行修改时,会使用当前读,即update之前先select数据库最新的内容,这就会导致幻读。所以说只保证select级别的幻读,看以下例子:
多版本并发控制:multi-versioned concurrency control,是MySQL中基于乐观锁理论实现隔离级别的方式,用于实现读已提交和可重复读取隔离级别的实现。在MySQL中,会在表中每一条数据后面添加两个字段:创建版本号:创建一行数据时,将当前系统版本号作为创建版本号赋值;删除版本号:删除一行数据时,将当前系统版本号作为删除版本号赋值。
聚集索引,B+树

叶节点并不存储数据,而是存储指向数据的指针。
非聚集索引

| 区别 | Innodb | Myisam |
|---|---|---|
| 事务 | 安全 | 非安全 |
| 锁 | 行级 | 表级 |
| 效率 | 低 | 高 |
| 索引 | 聚集索引 | 非聚集索引 |
| 外键 | 支持 | 不支持 |
| 使用环境 | 需要事务,大量增,改 | 多查询,不需要事务 |
请参考:https://computingforgeeks.com/how-to-install-mysql-8-on-ubuntu/
Arraylist的初始容量为10,一旦达到,将会按照原容量的50%进行扩容,即elementData数组的长度变为原来的1.5倍。
我们来看一下add(int index, Object e)这个方法:
1 | /** |
可以看到,使用了System.arraycopy方法,源数组和目标数组都是elementData,将index及其之后的元素复制到index+1的位置。
我们发现源码中用于保存元素的elementData的数组是被transient修饰的,这意味着他将不被序列化。那ArrayList是如何序列化的呢?我们可以发现,ArrayList自己实现了两个方法:readObject、writeObject用于自定义序列化,避免采用Java原生的序列化。那为什么要这么做呢?在writeObject方法中,可以看到只是将size范围内的元素进行序列化,这是由于前面讲过的扩容机制,导致elementData的长度大于size,size索引之后都不保存具体元素值(或者说只为数组初始化的值),但确已经申请了内存空间,如果全部序列化,那么将会浪费大量空间来存储这些无用的信息。我们可以通过下面一个例子来具体演示。
我们可以看到,一个长度为20000的数组只保存了5个元素,如果直接将这个数组序列化,大小是79kb,若只将5个元素序列化,序列化后的文件大小仅为1kb。
1 | import java.io.FileOutputStream; |

在Java 8及以后版本中,可以这么实现:
1 | import java.util.*; |
测试网站:https://www.lintcode.com/ai/creditcard_fraud/overview
信用卡虚假交易即指该交易有涉嫌非法套现的行为,即用户在商户刷卡后,商户不提供用户消费品而是把消费的钱通过现金的方式返还给用户同时抽取一部分费用作为佣金,虚假交易检测即给定某一交易数据,判定该交易是否是虚假交易。
数据集为2013年9月里某两天欧元区的信用卡交易记录。在这两天中共有284807笔交易,其中的492笔是欺诈。把欺诈交易的类(class) 认为是1,非欺诈交易的类认为是0。给定数据集中,正常数据有22万余条,虚假数据只有400多条,可见训练数据严重失衡,需要通过采取一些措施解决这种不平衡。
数据集里面有从PCA转换得到的28个features。之所以进行了PCA转换是因为不能把原始的消费者信用卡记录暴露给公众,这样触犯了用户的隐私。所以做PCA转换处理。可以简单理解为加密。
Features V1, V2, …, V28都是经过PCA转换后获得的features。没有被PCA转换的,保留了原始数据是”Time”和”Amount”。”Time”记录了每笔交易和第一笔交易(Time属性为0)之间的时间间隔,以秒为单位。”Amount”是交易数额。”Class”就是这笔交易的最终分类。
导入数据。
1 | import pandas as pd |
我们首先统计在不同的时间间隔内正常交易的数量和虚假交易的数量是怎样的。
1 | f, (ax1, ax2) = plt.subplots(2, 1, sharex=True, figsize=(12, 4)) |
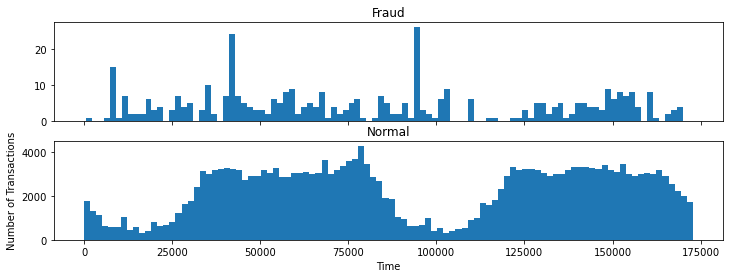
可以看到,正常交易有一个明显的周期性,而虚假交易呈现一个均匀分布的趋势。
我们再统计不同交易金额的交易数量。
1 | f, (ax1, ax2) = plt.subplots(2, 1, sharex=True, figsize=(12, 4)) |
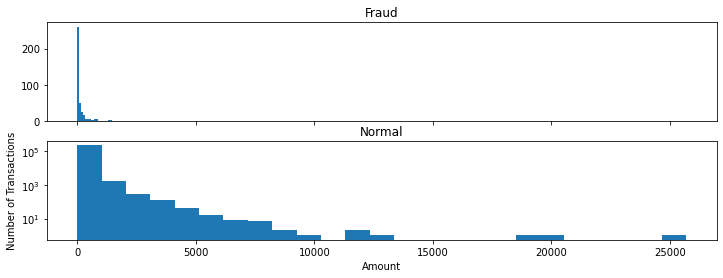
可以看到,正常交易的交易金额比虚假交易金额要大,虚假交易的交易金额最大不超过2500。
首先将“Time”、“Amount”这两列标准化,需要注意的是,训练数据标准化意味着测试数据集也需要标准化,要将二者置于同一尺度下才能较好的预测结果。注意:标准化的时候注意防止数据泄露!
1 | from sklearn.model_selection import train_test_split |
1 | from sklearn.preprocessing import StandardScaler |
对于样本类别数量极不平衡通常有过采样(over-sampling)、欠采样(under-sampling)两种方法。过采样用于扩增数据集,而欠采样用于减小数据集。
本例中,由于预测的数据在5万条,给定的训练数据中异常数据只有400条左右,如果做欠采样,需要使得正常数据与虚假数据数量相同,那么训练模型的数据大约为900条,这样训练出的模型大概率是欠拟合的,无法应对大规模测试集的情况。
因此,采用SMOTE算法对数据集进行过采样,使得虚假交易数据与正常交易数据相同。
1 | from imblearn.over_sampling import SMOTE |
模型尝试了LR、决策树、随机森林、XGBClassifier。最终随机森林在数据集上取得的分数最高为0.87。
1 | from sklearn.ensemble import RandomForestClassifier |
由于随机的原因分数误差在0.1上下。
优点:
缺点:
优点:
缺点:
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true